
Blog
A Playbook for IT Leaders Navigating a Volatile Compute & Storage Market in 2026:
Read More



Navigating the world of enterprise AI can feel like a race, but rushing to deploy new solutions without a strong security foundation is a fast track to disaster. Every additional AI model in an enterprise environment, from simple integrated chatbots to complex data analysis tools, introduces an expanding attack surface and new vulnerabilities. Traditional security measures weren’t built to handle the unique threats that come with AI, such as prompt injection attacks and data exfiltration.
This article serves as a practical guide for embedding security into enterprise AI strategies, examining real-world risks, and presenting actionable measures to ensure secure AI implementations, safeguarding both business operations and customer trust.
Generative AI is utilized by enterprises in varying and distinct ways. The AI Maturity Pyramid is a model for describing the maturity level of AI usage within an enterprise. This model helps scope AI conversations to be useful for the type of AI utilization that exists in the enterprise at the moment.
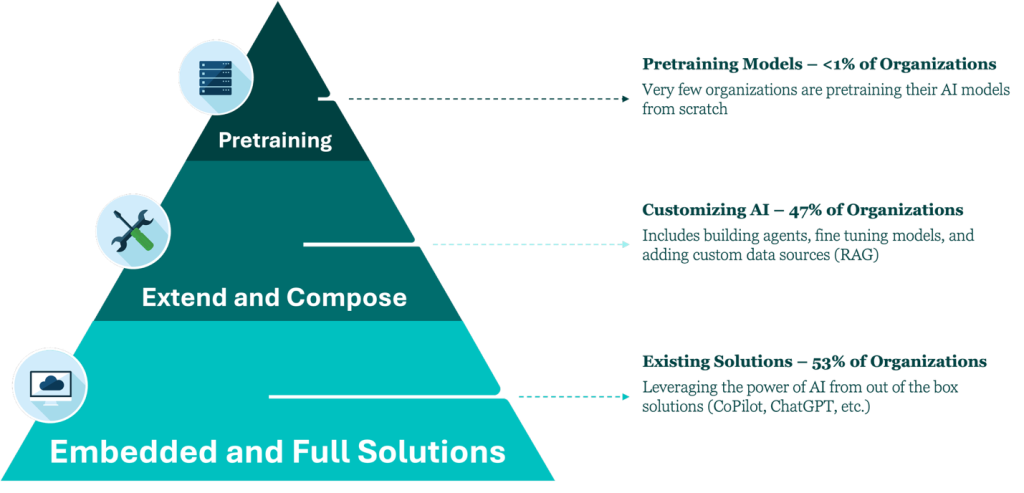
This post will focus on Level One – Utilizing embedded and holistic Generative AI solutions.
AI utilization by organization is still increasing year over year, McKinsey’s State of AI 2024 reports 72% of companies now use AI in at least one function—roughly three out of four—with 65% regularly using GenAI. Tactically, many start in Stage 1 (embedded copilots), then progress to Stage 2 as data readiness and governance catch up.
Securing AI needs a “both/and” mindset. AI introduces new risks while amplifying old ones. You’ll secure identity, access, and data as usual—and add AI‑specific controls (e.g., injection defenses, output handling, tool/agent guardrails).
Data is the core of any AI initiative—and the primary driver of scope, architecture, and control selection. Before designing user journeys, inventory what data the AI will see (business apps, documents, email, CRM, tickets), where it lives, who can access it today, and how it will flow at inference time (grounding, connectors, retrieval). This scoping is vital for sizing the project and for choosing the appropriate security controls.
To take a practical example of data scoping, suppose an organization is deciding to rollout CoPilot to all employees. The organization should be aware of what data CoPilot will have access to, and audit data permissions to ensure data is not overly shared. By default, CoPilot inherits the permissions in the Microsoft environment. By understanding that, the organization can audit M365 data to ensure CoPilot will only access data that it is supposed to, and that end users can only access data that is appropriately shared with them. If other data sources are going to be manually connected to CoPilot, that extra data requires additional auditing. Understanding the data involved is crucial for scoping any AI project.
NIST’s AI RMF and GenAI Profile [CW1] provide a structured way to tie those data decisions to risk categories and control objectives across the AI lifecycle.
Automating data classification is key to effective data enforcement. Manual data labeling is ineffective at the scales of AI projects. Finding a strategy to scale data observability is core to AI observability.
Data labeling and classification is commonly done with Microsoft Purview. As the number of AI projects ramp up and become more sophisticated, you may consider looking at purpose-built solutions outside of Microsoft.
Identity & access still rule.
Using Microsoft Copilot as a practical example of an out of the box AI solution, CoPilot can only surface what a user is already permitted to access—so least privilege and permission hygiene directly affect “what AI can reveal.”
Overly permissive sharing is an easy way to unknowingly expose data. In the past, this overly exposed data had to be found, but AI like CoPilot will find and reference this data much faster.
An employee gaining access to sensitive HR data because the file was incorrectly shared with a larger group than intended can quickly escalate to legal concerns at best and malicious exfiltration at worst.
Auditing identities, data, and permissions is an important way to maintain security throughout the life cycle of AI in the enterprise.
Data loss prevention (DLP) now sits “in the prompt path.”
If an organization wants to enforce AI policies, gain observability into shadow AI usage, and add another layer of security, modern DLP tools that sit on the endpoint, in the browser, or on the network help gain insight into AI usage.
These tools can help enterprises understand what AI applications employees are using, how they are using them, and how the enterprise can invest in AI projects to help address these problems.
In Microsoft Copilot environments, Microsoft extended Purview DLP to Copilot experiences so admins can excludelabeled items from being summarized in Copilot responses (while still citing them) and even disable Copilot skills when a sensitive file is open in Office apps.
Automations & approvals.
When you configure Copilot (or any LLM) to perform actions, treat it like any privileged automation: require user consent for sensitive steps, enforce RBAC/service principals, and log/runbooks for SOCs. NIST’s RMF reinforces the need to define threat surfaces before enabling agency (write actions).
Traditional security controls are the foundation for AI security hygiene, but AI introduces unique threats as well. A secure enterprise environment with AI contains a holistic defense-in-depth combination of traditional security controls and AI specific security controls.
Even when using out of the box solutions, it is important to be aware of the unique risks AI presents. This includes supply chain security (being aware of what models are being used and their training sources), prompt injections (inputs that make AI behave in unexpected ways), and hallucinations (false data presented as true by the AI).
Depending on the agency of AI application, there are additional concerns. For example, if an AI application has agency to use tools and execute workflows, it’s important to understand the ‘blast radius’ of things the AI application has access to. As well as understanding how the tools interact with the AI. Often, additional tools (like Web Search), increase the attack surface of data that could potentially affect the AI’s responses in unpredictable ways in an attack called indirect prompt injection.
AI Risks in Detail:
Model & supply chain provenance.
Know which models that tools in the environment are running, their training sources, known limitations (bias/outdated data), and update cadence. OWASP’s LLM Top 10 calls out LLM03 Supply Chain and LLM04 Data/Model Poisoning—you’ll want vendor attestations and potentially internal validation gates (pre‑prod evals, regression tests) for any model update.
Hallucinations & fact‑checking.
Language models occasionally confidently report plausible but factually incorrect information. As models improve, hallucination rates are decreasing, but it is important to understand the data integrity risks and how that influences an AI initiative.
The best practice to “fact check” data today is to use retrieval-augmented generation (RAG) and enforce the AI to include citations to specific data. Human review is important for critical flows.
Prompt injection (direct & indirect).
Using an AI Firewall to monitor inputs, both direct and indirect, helps ensure prompts (whether they are malicious or not) do not cause unexpected behavior from the AI.
OWASP’s LLM01, from the OWASP Top 10 for LLMs, details the class and defense patterns and maintains a living specification.
Indirect attacks bury malicious instructions in external data (emails, web pages, documents) that your AI reads; they can hijack context and exfiltrate data or trigger unsafe tool calls.
Tool/agent abuse — “excessive agency” & tool poisoning.
As models are granted the ability to call tools (plugins, actions, MCP servers), it is important to constrain what can be done, validate inputs/outputs, and watch for contaminated tools (“tool poisoning”). OWASP LLM06 (Excessive Agency) and community research on MCP tool poisoning outline risks and mitigations like strict scoping, allowlists, consent walls, and output validation.
Observability, red teaming, and incident response.
Treat AI telemetry like any other high‑value workload: capture prompts, model IDs, tool calls, and rule hits; centralize into SIEM; tune detections for AI‑specific TTPs (e.g., bursts of blocked prompts, anomalous tool invocation). For proactive hardening, leverage AI Red Teaming Service to exercise jailbreaks, indirect injection, and data exfil paths before going live.
Choosing solutions that fit your risk tolerance.
Gartner highlights that a significant share of organizations buy rather than build (only ~38% develop their own apps) and recommends combining traditional controls with specialized AI defenses as maturity grows. That aligns with a pragmatic roadmap: start where your existing controls are strongest (embedded/copilot), then layer AI‑specific defenses as you extend and compose.
AI is already reshaping enterprise automation and knowledge work. Start with data—catalog what AI will touch, how it’s accessed, and how it will flow—to right‑size the project and the architecture. As you scope initiatives, pair traditional security (identity, least privilege, DLP) with AI‑specific controls (prompt‑injection defenses with AI firewalls, tool/agent scoping, output validation). Finally, select solutions that align to your risk tolerance and maturity: embedded copilots for quick wins, extended architectures for domain value, and full custom/agentic systems only when your governance, defenses, and SOC visibility are ready.
Reach out to hello@sayers.com if you are interested in a deeper risk conversation.

