
Blog
Cybersecurity Consolidation and Platformization: Strategic Insights for CISOs
Read More



Utilizing AI in internal enterprise environments involves numerous considerations. This technical brief separates AI conversations into three distinct areas:
1) Utilizing Existing Solutions
2) Customizing AI Workflows
3) Pretraining
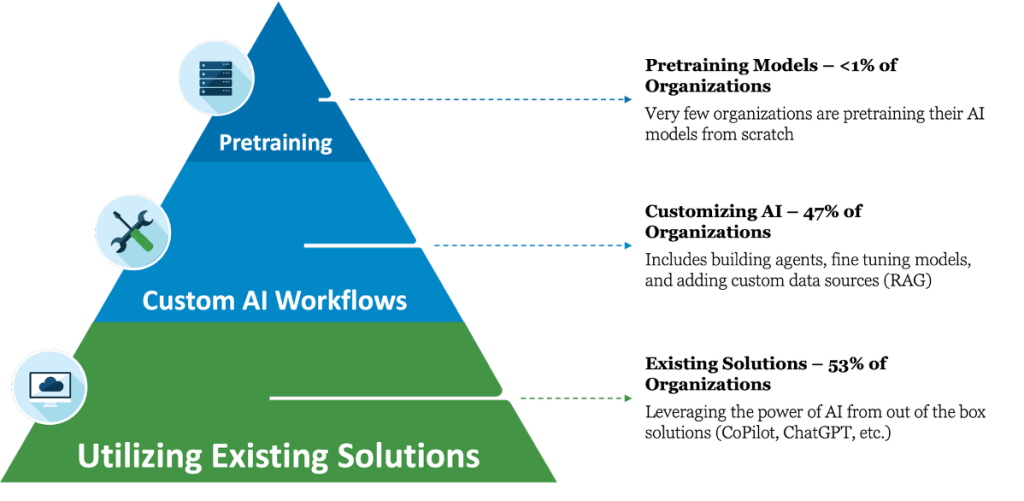
This graphic illustrates the three stages of enterprise AI usage. The bottom of the pyramid is Utilizing Existing Solutions. Enterprises will typically begin their AI initiatives at this stage, and progress to the next stages as their AI posture matures.
This technical brief will focus on the second area – creating Custom AI Workflows. Specifically, what it takes from an operational and a security perspective to build an AI powered application.
This brief does not cover training the actual model itself, but rather how to build the surrounding components necessary to create a functional application around a model file.
The Core Components to AI Applications
“AI model file,” which contains the core intelligence of the model, lacks built-in functionality for receiving input, displaying output, fine-tuning, or other features typically associated with generative AI.
The following diagram illustrates the most basic steps required to interact with a model:
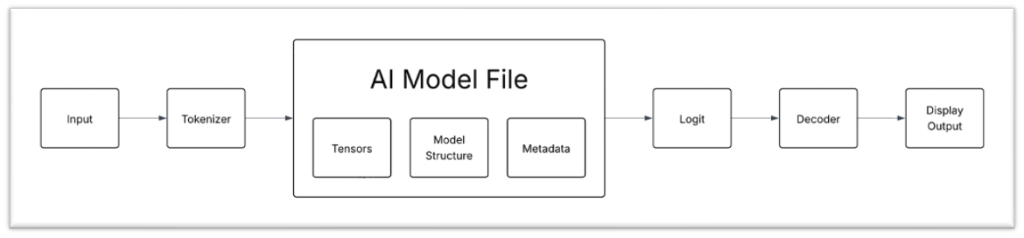
The basic steps to achieve a successful AI application are:
• Pretraining a model from scratch is out of scope for most AI applications and enterprise AI initiatives. Therefore, finding the base model that best fits the use case(s) is an important first step.
• This base model may be accessed through an API like a ChatGPT model from OpenAI or you may choose to download a model that is available to be ran locally that can be found on model repository sites such as Hugging Face.
Input
• This can be input from an end user, an AI agent, or another workflow.
Tokenizer
• Tokenization – The process of breaking user input into smaller chunks that will be put through the model one “chunk” at a time.
• Encoding – AI models can be viewed as computing very difficult numerical sequences. So, the individual tokens or “chunks” are encoded into numbers that the model can perform operations on.
AI Model
• Once our input is tokenized and encoded, it is ready to be passed off to the base model.
Logits
• The model will output logits. These are effectively lists of the most probable tokens as opposed to outputting one static token.
• Temperature – Selecting more or less probable tokens from the ‘list’, increasing or decreasing the randomness of the output.
Decoder
• Converts the tokens that are currently in numerical form back into human readable text.
Display Output
• The human readable form is displayed to the user to work with the data.
• In the case of Agentic Applications, the output can be used to call other workflows and interact with other applications.
Every step of the way, except the pretrained model itself, is a step that must be solved for. That means either building a custom solution or finding an existing tool to do it for us. Each step of the way also means room for error, which is where the security concerns come in.
There are a variety of ways to utilize an existing pretrained model. It is possible to use an API call directly to a model provider like ChatGPT, to go through a cloud platform that exposes these large models (i.e. Azure AI Foundry or Amazon Bedrock), or to download a model to use locally from a model repository website like Hugging Face.
The largest models such as OpenAI’s GPT-4, GPT-5, and GPT-4o can only be accessed through API calls or the Azure OpenAI Service. The proprietary nature and the large scale of these models demand specialized infrastructure that OpenAI will maintain complete control of. To utilize these models, or models of this scale from other companies like Anthropic’s Claude or Google’s Gemini, that will typically require API calls.
Another option is to use a cloud service that exposes these top models. These tools will broker API access that we can build our custom application or workflows around. Anthropic’s Claude is available through Amazon Bedrock while ChatGPT’s GPT models are available through Azure AI Foundry.
The final option is to download a model to utilize locally. There are large model repositories online that offer pretrained models across modalities. For smaller or more specific use cases, there may be a model that already exists that can be leveraged. Hugging Face is currently the largest AI collaboration hub.
Downloading existing models for local use comes with additional considerations. First, the physical infrastructure the models runs on must be provided. That often means expensive compute and large networking infrastructure. Utilizing models from unknown sources also introduces potential security concerns.
To understand the additional overhead of utilizing local models in enterprise environments, let usstart by reviewing how models are saved to permanent storage. When an AI model is running in memory, it is effectively a set of large multi-dimensional arrays of numbers, these are called tensors. These individual numbers are the weights that get tuned during training. Once all of thenumbers are trained and tuned to the use-case, the challenge is to save the structure and values of these tensors.
So, to save a model, you must find a way to turn this tensor object into a file that you can save to disk, so it can be used in more places than just the original script that trained the model. The programming language used to develop the model and how you plan to interact with the model both impact how you save the model.
Python Serialization uses Python’s pickle module to serialize Python objects to save objects to disk. An AI model is a set of tensors that we can perform this serialization on.However, since any Python object can be serialized, threat actors can serialize malicious code and attempt to distribute it as a standard AI model binary.
Safetensors is a model format developed by Hugging Face to solve for Python’s pickle security concerns. Safetensors are built to only serialize and deserialize tensors. This prevents any other objects, such as malicious code, from being executed. Safetensors are also generally more efficient and can be faster for large workloads.
Be aware of the risks associated with using models from the internet and how the format of the model file affects those risks.
The AI model is a part of the AI application attack surface. Whether the model file is coming from a proprietary model provider like OpenAI or the model is from an online model repository source, the risks associated with our choice must be considered.
Now that a model has been decided on, you are ready to start sending information through it. That means you must perform two big steps: 1) Find a way to obtain input, whether that is from an end user or from a different automated process and 2) translate the input into something the model can understand and work with.
Input can be gathered from an end user. For example, if we take a chatbot AI application like ChatGPT, the input is gathered in a frontend textbox through a website.
Another option is to have input get generated from an automated process. If the AI application is going to have agentic functionality, one could gather input from a script that fetches data from an internal data source.
End user input is the first and most important piece of the attack surface. Anytime input is being gathered from an end user, extra precautions must be put in place to ensure input is valid, not malicious, and the responses from the application are appropriate. Malicious users will use theinput method to attempt to break various pieces of the application. This can involve attacking theinput boxes directly. This type of attack can be defended against with historical input defense techniques, for example, sanitizing all inputs and not allowing any form of code execution from any input.
Attackers could also potentially try to use the input to the AI itself to create malicious code, malicious prompts, find vulnerabilities, or exfiltrate data. Model guardrailing often happens later in the pipeline, but one must ensure that input sanitization is being performed on any and allinputs similar to other end-user facing application.
Input is typically gathered in a human readable format like text. AI models do not understand text, they are math functions that understand numbers. The next step in the AI application is turning our human readable input into AI readable input.
Tokenizing is the process of chunking the input into chunks then encoding those chunks into an AI readable format. The challenge is to chunk large text inputs into small enough pieces that we have a lot of context without too small of pieces that would require too large of context windows. In this stage it is very important to balance efficiency and preciseness.
If input is chunked into ‘too large’ of pieces, you may lose context on what each piece actually means. If chunking input into ‘too small’ of pieces, it could increase the computational cost analyzing every small bite and we may not have the context size to analyze enough bites to get the whole picture, which would result in lost context of the message.
Humans do this very naturally. When we read, we don’t scrutinize every single letter and white space. Instead, we jump through the whitespace when it makes sense, like at the end of a page. We wouldn’t scan the whitespace character by character waiting for the next word. We see the empty space as one large empty area, and we just flip the page. We also tend to skim through words, this is why typos can occasionally be tough to see.
There are a lot of different philosophies for tokenizers. The model’s use case has large implications for how you want to tokenize data.
If you wanted to create a model that generates passwords, you may want a tokenizer that breaks words down into each character. The model will then output ‘chunks’ at a character level.However, doing things one character at a time vastly limits the amount of context the model canunderstand.
If you wanted to be more efficient for larger pieces of text, potentially creating a model to write English chapter books, you could tokenize input by the word or separating words by whitespace. This works well for well structured, pre edited English words. But what happens when there is a typo? Or if you want to perform math or output programming code? In those cases, the word-by-word tokenization loses a lot of efficiency.
Most modern general purpose LLMs, like ChatGPT and CoPilot, use a technique called Byte-Pair Encoding (BPE). BPE is a clever way to get the best of both worlds as it starts by breaking words into individual characters, then slowly merges the most common individual characters. By the end of this complicated process, common words are merged into single tokens, and more complicated words get split into context rich sub-words.
There are a lot of tools you can use to visualize how the most popular tokenizers split differently.I am going to use an open-source tool created by Guillaume Laforge to illustrate how Gemini tokenizes words. You can find the source code for this tool here.
An example input text to illustrate how the Gemini tokenizer would break the input down is as follows. Note the handling of misspellings, any longer words, and the numbers included. Here is the prompt:
“This is an example prompt. You can see how words and sometimes subwords get broken down. Watch how the tokenizer deals with less common text chunks such as math and typos. Typos require more context, Otherwsie mispellings can get misconstrued. What is 2643 + 3212 divided by 2?”

You can see, common words are understood as one token including the space before the word. However, longer words get split into subwords, or misspellings get split into smaller pieces as well. This increases the amount of context the model can work with.
Another interesting thing to note is how the numbers are tokenized. It is important to think of the context a model will be used when picking the tokenization technique. Being able to parse different inputs to make effectively sized tokens is an interesting problem. Math functions, programming languages, and different human languages all may require slightly different tokenization philosophies to find the right middle ground between efficiency and context.
This part of the AI applications requires one to deploy the same tokenizer used during pretraining of the original model itself. Once you identify the original tokenizer and have a way to use it, you can send inputs through it. Then, take the output from the tokenizer and send that through the model.
Just like the other steps of the AI application process, the tokenizer step is another piece of theattack surface. If a malicious user has access to this step in the pipeline, they could use a different tokenization technique that is similar to the tokenizer used to train the model so that the model still maintains a level of understanding, but the differences will cause unpredictable outputs. This vulnerability has been demonstrated in attacks known as “Adversarial Tokenization”. Using a different tokenizer will have an especially negative impact on security guidelines and other guardrails around the model.
A plausible extension of using a different tokenizer would be using an intentionally malicious tokenizer. Although this hasn’t been demonstrated yet, it doesn’t seem unreasonable for a large resource threat actor to replicate a common tokenizer but manually change certain encodings to deliberately and repeatably shift how the model behaves when that specific input is given.
Another attack that starts from the input but is meant to target the tokenization would be hiding characters that will get parsed by the tokenizer that the end-user may not even notice. This is called “invisible prompt injection”. It could involve prepending invisible unicode character to a prompt to attempt to change the behavior of the models output. Again, this is a way to attempt to get around model security features and guardrails.
Models output “logits” instead of individual tokens. These logits are probability distributions of tokens. This means, rather than getting one token to work with, the model outputs a list of the most likely tokens and how likely it expects each one to be. Although this adds another step of complexity, it also allows the adjustment of the ‘randomness’ of the outputs.
This is what the ‘temperature’ parameter controls. If you have ever played with a temperature slider on an AI website, you know that lower temperatures result in more deterministic results (more consistent, less random) and higher temperatures result in much more random and even less coherent results.
This is incredibly helpful when finetuning AI for different tasks. Workloads that require high levels of precision like writing code can be set to lower temperatures; where workloads that require more randomness like an idea generator for blog posts or a sales email writing assistant may perform better with higher temperatures.
To review the process, a model would generate a logit, pick a token from the logit (thetemperature parameter can affect this), use that token to build its context window, and generate another logit from its new spot until it either generates a stop token or some sort of stop sequence is executed.
So, the effort here is much smaller. You are only providing adjustments on how the logits are interpreted by the model. This means the attack potential at this point is much lower. Possibilities predominately include internal threat actors shifting this number during the AI development to produce unwanted results.
Finally, as the end of the pipeline is reached, the model friendly encoding (the numbers that correlate to each token) turn back into human readable words. This step is a reversal of theencoding step.
Once you decode your output, you can display it to the user, and it is done! From a security perspective, these are standard problems. Make sure when decoding output, there is sanitization,so code is not getting executed. And to always ensure the output window that the end-user sees,whether that is a web browser or an application or a terminal, has no way to interact with the actual backend directly.
AI systems are inherently complex. Even using a pre-trained model can be a complex process, involving numerous operational and security considerations. This brief provides a foundational overview of the essential building blocks required to run an AI application.
While not covered in this brief, enhanced features such as Retrieval-Augmented Generation (RAG), which allows integration of local data sources into existing models, build upon these fundamental components.
If your enterprise would like to learn more about AI, AI solutions, or is interested in AI forenterprise environments, contact us at hello@sayers.com. Stay in touch with the Sayers blog for future discussions around AI!

