
Blog
HPE Discover 2026 Highlights: Networking First, Private Cloud for AI, and Practical Ways to Navigate a Volatile Infrastructure Market
Read More


When enterprises evaluate new technology, they face a familiar balancing act: build in-house, buy a point solution, or pursue something in between. In the world of AI, pretraining a model from scratch promises total control, although an appealing prospect on paper, that control comes with staggering costs: not just in compute and talent, but also in operational complexity and security risk.
Pretraining models from scratch is the highest level of AI Maturity. The progression of AI usage in internal enterprise environments is demonstrated in the AI Maturity Pyramid:
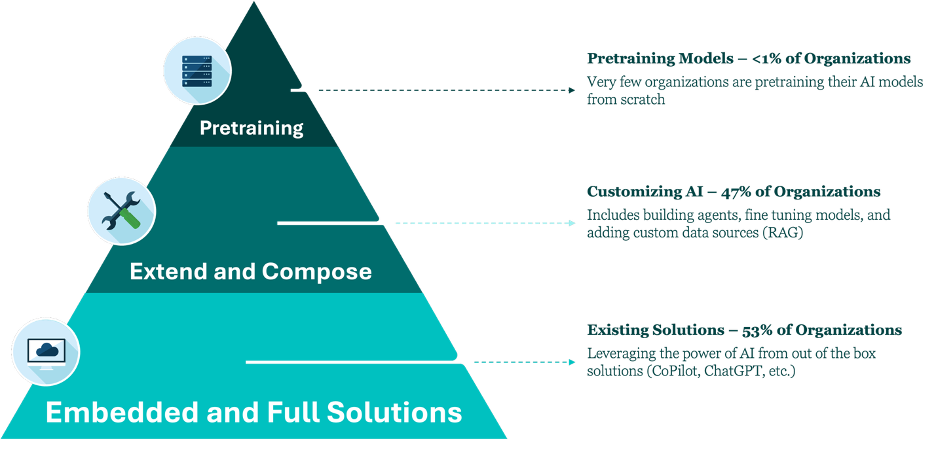
This post will focus on the top level and will demonstrate various operational and security considerations that illustrate the demanding costs of pretraining foundation AI models.
Before diving into pretraining considerations, it is important to demonstrate what finetuning is capable of. Finetuning can take an already pretrained model and teach it new skills (like a programming language), new functionality (like how to Google information or how to execute Python code and output the response), and generally can be molded to niche specifications.
Often, when building AI applications comes up, the question is: do we build a foundation model from scratch (pretraining), or do we refine an existing model to our domain (finetuning)? The trade-offs are steep, especially in the context of enterprise deployments and security-conscious applications.
• Pretraining is the process of training an AI model from scratch (or near-scratch) over enormous, generally weakly curated datasets (i.e. web crawls). The goal is to build a model with broad, general-purpose capabilities and representations (linguistic, visual, multimodal) before specialization.
• Finetuning (or transfer learning / domain adaptation) takes that pretrained base model and further trains it on a more focused, curated, often labeled dataset, tailoring it to a particular domain or task.
From a cost perspective, the difference is vast:
• Pretraining at modern scales often costs tens to hundreds of millions of dollars in compute, hardware, energy, and operational overhead.
• In contrast, finetuning (especially if done optimally, e.g. parameter-efficient fine-tuning, adapters, prompt tuning) can sometimes be done for thousands, or in some limited cases, even hundreds of dollars (depending on dataset size, compute availability, and infrastructure) once a suitable base model exists.
Because of this gap, most enterprises should strongly assess whether their AI goals can be met via finetuning (or hybrid approaches) before taking on the burden of full-scale pretraining a foundation model.
That said, the appeal of pretraining is control and differentiation: owning a full foundation model enables proprietary architectures, full data pipelines, bespoke model behavior, and the intellectual property to tightly lock in advantage in a narrow domain. But only large tech labs or resource-rich organizations typically have the appetite and resources to undertake that.
Operational Considerations – Dealing with Massive Scale
When the decision to build at scale is made (or at least strongly considered), several operational challenges loom. These are less glamorous than the “cool model architecture” phase, but far more likely to make or break the project.
Volume, Diversity, and Licensing
To build a capable foundation model, you need vast amounts of data (hundreds of terabytes, petabytes or more), but simply “more data” is insufficient; it must be diverse, high-quality, and governed by appropriate licensing. As data protection laws (e.g. GDPR, CCPA, evolving AI data usage rules) tighten, assembling legally usable datasets becomes more difficult.
Authenticity, Provenance, and Poisoning
At scale, verifying authenticity is nontrivial. How do you know that scraped documents are not malicious, copyrighted, or containing adversarial backdoors? In fact, research suggests that even very small proportions of malicious documents can poison a model. For example, a recent study by Anthropic (the company that created Claude), indicate that as few as 250 malicious documents can degrade or sabotage model of any size.
Moreover, adversarial attacks, backdoor insertions, and dataset poisoning are well-known threats in AI supply chain research.
Data Engineering at Scale
Once data has been acquired, processing terabytes to petabytes of data is nontrivial:
• Deduplication: Ensuring the model isn’t trained repeatedly on the same content, which can distort weighting and lead to overfitting or memorization.
• Filtering / cleaning: Removing low-quality, offensive, toxic, biased, or hallucination-prone content.
• Leakage avoidance: Ensuring that training data doesn’t inadvertently include test or evaluation sets, or sensitive internal content that could leak.
• Sharding, partitioning, versioning: Infrastructure to manage evolving datasets over time.
Engineering these pipelines reliably is a major undertaking by itself.
Once the data is ready, you must scale out compute:
• GPU / TPU clusters: The scale of pretraining demands hundreds or thousands of accelerators. Model parallelism, pipeline parallelism, and memory sharding are essential.
• High-performance networking: Necessary to connect the compute demanding high bandwidth and low latency. Without this, communication becomes the bottleneck.
• Storage I/O and caching: Feeding data fast enough to those accelerators, with efficient caching layers, data loaders, prefetching, etc.
• Fault tolerance & spot instances: At scale, failures are frequent. The system must tolerate node failures, preemption, and reconvergence.
• Energy and cooling: The power draw and thermal constraints in real data centers become nontrivial.
The complexity here is not incremental; rather it’s multiplied. Many AI labs spend more on managing compute infrastructure and orchestration than on the model logic itself.
After data and compute are in place, the orchestration and tooling become the next frontier:
• Talent demand: You need top-tier ML engineers, infrastructure engineers, site reliability engineers (SREs), and MLOps staff, who command premium salaries. Without top talent to properly utilize the infrastructure worth tens of millions, progress can become severely hamstringed.
• Software stack orchestration: Building or integrating custom frameworks (e.g. distributed training frameworks, efficient mixed precision, checkpointing, gradient accumulation, optimized kernels).
• Experiment tracking, versioning, model registry: To keep track of hyperparameters, data versions, architecture variants, and reproducibility.
• CI/CD for models: Testing, validating, rolling back model versions, A/B testing, rollouts.
• Monitoring, drift detection, retraining triggers: Detect when model performance degrades, or when the domain shifts.
• Security, Audit, Governance: Audit trails on who changed which data/model, configuration controls, access management, and “defense in depth” for model pipelines.
In aggregate, this layer is where theory meets the hard grind of production-grade reliability, scale, and security.
Large-scale AI projects magnify upsides AND risk. For cybersecurity-oriented organizations, the stakes are especially high: model compromise, intellectual property theft, data leakage, and adversarial attacks are real.
• Confidentiality and access controls: When users are accessing the AI platform, it is necessary to maintain confidentiality between separate chats and data. Strict role-based access and data isolation are prerequisites.
• Data leakage & memorization: Modern Large Language Models (LLMs) sometimes “remember” rare inputs, especially from small, unique documents. That can lead to unintentional leakage of proprietary or private information during inference.
• Poisoning / backdoors: The dataset pipeline is a target for attackers to insert malicious triggers or backdoors (for example, embedding phrases that cause the model to leak data or behave maliciously).
• Probe attacks & membership inference: Attackers may be able to query or reverse engineer models to determine whether a specific data record was part of training.
• Trust in labeling & contractors: If you outsource labeling or data preprocessing, those third parties become part of your threat surface.
• Hardware-level vulnerabilities: Researchers have identified side-channel or power-based attacks (e.g. “GATEBLEED”) that leak traces of whether certain data was processed.
• Model and library supply chain risk: Pretrained model artifacts, dependencies, or libraries (e.g. from PyPI, NPM, Hugging Face) may themselves be trojanized or malicious. Attackers may embed malicious code in model files (serialized objects) that execute on deserialization or inference time.
• Dependency graph vulnerabilities: Studies of the large language model software supply chain show that a few core “hub” components (e.g. transformers library) influence many downstream packages, meaning a vulnerability in one core library can cascade broadly.
• Compromised updates / firmware: The supply chain for hardware, firmware, or accelerators is itself vulnerable. A malicious firmware implant or backdoored accelerator chip could undermine the entire system.
• Malicious model insertion: Attackers may inject fully malicious or trojanized models into your development pipeline or MLOps tooling, masquerading as innocuous pre-trained models. Such models can execute unauthorized behaviors or exfiltration when deployed.
• Insider threats & access abuse: With many engineers, contractors, and data scientists involved, enforcing principle-of-least-privilege and segmentation is critical.
• Model theft & inversion: A competitor or adversary may try to steal your model (weights, architecture) or approximate it via model extraction or distillation. This is a common technique that offers incredibly cost-effective alternative models that may impact business (i.e. Distilled models offered by DeepSeek).
• Ownership disputes & licensing leaks: If parts of your model or data are derived from open-source or third-party sources, the legal and licensing boundaries must be tightly managed.
• Tampering, drift, and “silent” degradation: Over time, your model weights or pipelines could be tampered or corrupted (whether accidentally or maliciously). Detecting unauthorized changes is a simple task.
• Adversarial attacks on inference: Even a “perfectly trained” model can be manipulated in deployment by carefully crafted inputs to force misclassification, evasion, or leakage.
Every component, from the data, hardware, via libraries, to final model serving, represents a potential attack surface. Securing them demands a defense-in-depth approach.
Given the complexity and risk, here are some guiding principles and best practices tailored to organizations (especially in cybersecurity domains) considering serious AI investments.
Rather than jumping into building a foundation model, start with small, high-leverage use cases:
• Proof-of-concept finetuning: Identify a specific domain (e.g. threat analysis, SOC automation, anomaly detection, log summarization) and finetune an existing model to validate performance improvements, ROI, and risk boundaries.
• Retrieval-Augmented Generation (RAG) or prompt engineering: In many cases, combining a pretrained model with retrieval from your secure enterprise knowledge base is sufficient, avoiding full finetuning or retraining.
• Guardrail / red-teaming layer first: Embedding safety, filters, adversarial testing, and red-teaming early helps prevent surprises down the road.
Once the value is demonstrated, scale up gradually and invest in the supporting infrastructure, tooling, and security from the start.
• Data provenance and traceability: Always track data lineage, versioning, and who approved which sources.
• Supply chain vetting (“Know Your Supplier”): Require cryptographic signing, hash validation, and audit trails for models, code, libraries, and hardware. Use solutions to automate this process during the application development phase.
• Secure MLOps pipelines: Include static and dynamic scanning of model artifacts, dependency scanning, code audits, and continuous validation.
• Segmentation and least privilege: Separate environments for training, validation, inference, and limit access to sensitive components.
• Continuous monitoring & anomaly detection: Monitor model behavior, drift, performance degradation, and logs for deviation from expected patterns.
• Red teaming & adversarial testing: Regularly attempt to break the model (poisoning, inference attacks, backdoors) and harden defenses.
• Legal and compliance guardrails: Understand data licensing, IP boundaries, export controls, privacy, and auditing requirements.
• Fail-safe / rollback mechanisms: Be able to disable or revert to safe fallbacks if model behavior becomes unsafe.
Taken together, these practices form a framework for progressively scaling AI systems while controlling risk.
The decision between pretraining vs finetuning is foundational. Finetuning is often far more cost-effective and lower risk for many enterprise use cases; pretraining offers differentiation but demands huge investment and infrastructure.
Before pursuing pretraining, ensure all internal AI use cases cannot be met through finetuning and other post training techniques first.
Operational challenges in scaling AI revolve around data, compute, and engineering tooling,and they are far more difficult than they sound.
The security landscape in AI is an endless minefield: data breaches, poisoning, supply chain compromise, model theft. Every step of the pipeline is vulnerable.
The safest approach is incremental, use-case–first growth, combined with defense-in-depth, provenance, supply chain validation, and rigorous security processes.
If you would like to have more conversations around how your organization can accomplish their AI goals, contact us!

